Streaming ChatGPT Responses With Phoenix LiveView
This post is adapted from Streaming GPT-3 Responses with Elixir and LiveView.
Streaming ChatGPT API Responses
If you’ve worked with the OpenAI API in the past (especially the larger models), request latency can be a significant detriment to user experience. One way to overcome this is taking advantage of OpenAI’s ability to stream tokens in batches as data-only server-sent events.
This article shows you how to use HTTPoison to stream large HTTP responses. Fortunately, this same paradigm works for streaming server-sent events from the OpenAI API. We can rework the logic in the linked article to convert OpenAI responses into streams of tokens:
defmodule StreamingText.OpenAI do
require Logger
def stream(prompt) do
url = "https://api.openai.com/v1/chat/completions"
body = Jason.encode!(body(prompt, true))
headers = headers()
Stream.resource(
fn -> HTTPoison.post!(url, body, headers, stream_to: self(), async: :once) end,
&handle_async_response/1,
&close_async_response/1
)
end
defp close_async_response(resp) do
:hackney.stop_async(resp)
end
defp handle_async_response({:done, resp}) do
{:halt, resp}
end
defp handle_async_response(%HTTPoison.AsyncResponse{id: id} = resp) do
receive do
%HTTPoison.AsyncStatus{id: ^id, code: code} ->
Logger.info("openai,request,status,#{inspect(code)}")
HTTPoison.stream_next(resp)
{[], resp}
%HTTPoison.AsyncHeaders{id: ^id, headers: headers} ->
Logger.info("openai,request,headers,#{inspect(headers)}")
HTTPoison.stream_next(resp)
{[], resp}
%HTTPoison.AsyncChunk{id: ^id, chunk: chunk} ->
HTTPoison.stream_next(resp)
parse_chunk(chunk, resp)
%HTTPoison.AsyncEnd{id: ^id} ->
{:halt, resp}
end
end
defp parse_chunk(chunk, resp) do
{chunk, done?} =
chunk
|> String.split("data:")
|> Enum.map(&String.trim/1)
|> Enum.reject(&(&1 == ""))
|> Enum.reduce({"", false}, fn trimmed, {chunk, is_done?} ->
case Jason.decode(trimmed) do
{:ok, %{"choices" => [%{"delta" => %{"content" => text}}]}} ->
{chunk <> text, is_done? or false}
{:ok, %{"choices" => [%{"delta" => _delta}]}} ->
{chunk, is_done? or false}
{:error, %{data: "[DONE]"}} ->
{chunk, is_done? or true}
end
end)
if done? do
{[chunk], {:done, resp}}
else
{[chunk], resp}
end
end
defp headers() do
[
Accept: "application/json",
"Content-Type": "application/json",
Authorization: "Bearer #{System.get_env("OPENAI_API_KEY")}"
]
end
defp body(prompt, streaming?) do
%{
model: "gpt-3.5-turbo",
messages: [%{role: "user", content: prompt}],
stream: streaming?,
max_tokens: 1024
}
end
endThis logic more-or-less follows from the article; however, we need some special logic for handling data returned from the API. Each event from the API is prefixed with a data: <data> where <data> can be [DONE] or JSON data. During my experiments, I noticed that at times the stream receives multiple messages at once, so just calling Jason.decode! on the response will break. parse_chunk/2 splits responses on data and then handles both additional tokens and termination tokens.
Streaming Text in LiveView
The stream/1 function returns a stream from an HTTP request to the OpenAI API. We can use this stream in a LiveView to render the stream as the API returns tokens. Start by adding a new live route:
live "/answer", AnswerLiveIn a new LiveView, add the following mount and render callbacks:
defmodule StreamingTextWeb.AnswerLive do
use StreamingTextWeb, :live_view
import StreamingTextWeb.CoreComponents
@impl true
def mount(_session, _params, socket) do
socket =
socket
|> assign(:question, "")
|> assign(:answer, "")
|> assign(:state, :waiting_for_question)
|> assign(:form, to_form(%{"question" => ""}))
{:ok, socket}
end
@impl true
def render(assigns) do
~H"""
<div class="flex flex-col max-w-4xl min-h-screen items-center">
<h1 class="text-2xl">Ask Me Anything</h1>
<.simple_form
for={%{}}
as={:question}
:let={f}
phx-submit="answer_question"
class="w-full"
>
<.input
disabled={@state != :waiting_for_question}
field={{f, :question}}
value={@question}
type="text"
/>
<.button
type="submit"
disabled={@state != :waiting_for_question}
phx-disabled-with="Answering..."
>
Answer Question
</.button>
</.simple_form>
<div class="mt-4 text-md w-full">
<p><span class="font-semibold">Question:</span> <%= @question %></p>
<p><span class="font-semibold">Answer:</span><%= @answer %></p>
</div>
</div>
"""
end
endThis will create a simple form which we can use to submit queries to OpenAI and stream responses back. Next, add the following event handler to handle form submission:
@impl true
def handle_event("answer_question", %{"question" => question}, socket) do
prompt = prompt(question)
stream = StreamingText.OpenAI.stream(prompt)
socket =
socket
|> assign(:question, question)
|> assign(:state, :answering_question)
|> assign(:response_task, stream_response(stream))
{:noreply, socket}
end
defp prompt(question) do
"""
Answer the following question.
Question: #{question}
Answer:
"""
endThis will build a prompt, create a response stream, change the current state and invoke a stream_response/1 function and assign the result to :response_task. Next, implement stream_response/1 like this:
defp stream_response(stream) do
target = self()
Task.Supervisor.async(StreamingText.TaskSupervisor, fn ->
for chunk <- stream, into: <<>> do
send(target, {:render_response_chunk, chunk})
chunk
end
end)
endThis will spin up a new task to consume the OpenAI stream and send chunks to the LiveView process. You’ll need to start your task supervisor to your supervision tree:
children = [
# Start the Telemetry supervisor
StreamingTextWeb.Telemetry,
# Start the Ecto repository
StreamingText.Repo,
# Start the PubSub system
{Phoenix.PubSub, name: StreamingText.PubSub},
# Start Finch
{Finch, name: StreamingText.Finch},
{Task.Supervisor, name: StreamingText.TaskSupervisor},
# Start the Endpoint (http/https)
StreamingTextWeb.Endpoint
# Start a worker by calling: StreamingText.Worker.start_link(arg)
# {StreamingText.Worker, arg}
]Next, you need to handle the :render_response_chunk messages:
@impl true
def handle_info({:render_response_chunk, chunk}, socket) do
answer = socket.assigns.answer <> chunk
{:noreply, assign(socket, :answer, answer)}
endThis will receive the :render_response_chunk messages and append the next chunk to the current answer, which will then re-render in the browser. Finally, you need to await on the result of the task in a separate handler:
def handle_info({ref, answer}, socket) when socket.assigns.response_task.ref == ref do
socket =
socket
|> assign(:answer, answer)
|> assign(:state, :waiting_for_question)
{:noreply, socket}
end
def handle_info(_message, socket) do
{:noreply, socket}
endAnd that’s all you need. Now you can open the browser and try it out:
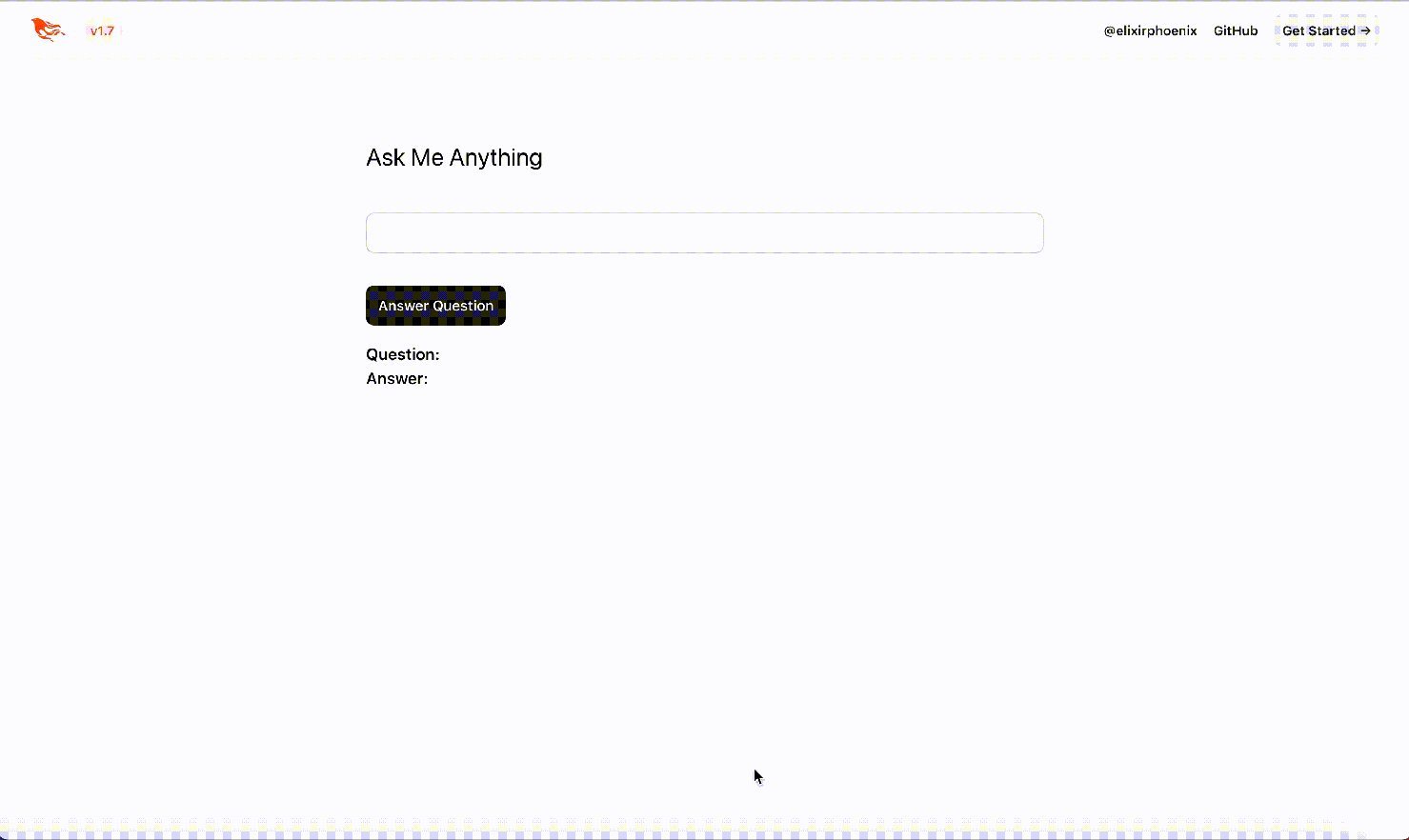
Success!
Enjoyed this post?
Subscribe for more!
Get updates on new content, exclusive offers, and exclusive materials by subscribing to our newsletter.